머신러닝을 공부하거나 AI를 활용하려고 할 때
가장 먼저 부딪히는 개념 중 하나가 바로
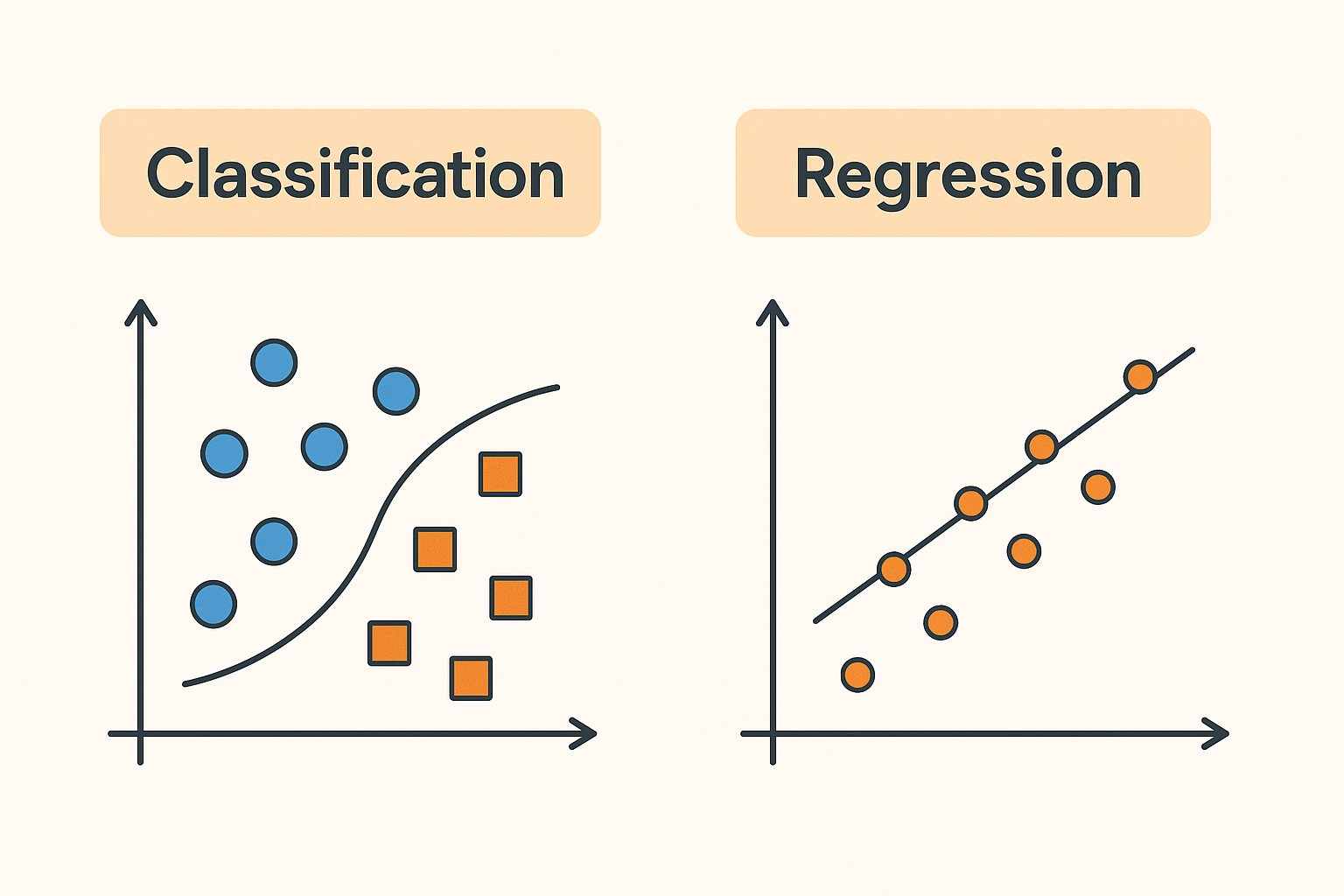
‘분류’와 ‘회귀’의 차이입니다.
둘 다 예측하는 기술이지만,
예측하는 ‘값’의 성격이 다르고
적용되는 문제 유형도 다릅니다.
이 글에서는 **분류(Classification)**와 **회귀(Regression)**의 차이를
비전공자도 한 번에 이해할 수 있도록 쉽고 명확하게 정리해드립니다.
1. 둘 다 ‘예측’이다
먼저 공통점부터 확인해 볼까요?
| 항목 | 분류 (Classification) | 회귀 (Regression) |
| 목적 | 값을 예측함 | 값을 예측함 |
| 사용법 | 머신러닝 모델 학습 | 머신러닝 모델 학습 |
| 입력 | 동일 (숫자, 텍스트 등 특징 데이터) | 동일 |
| 차이점 | 예측 결과가 ‘종류’ | 예측 결과가 ‘숫자’ |
✅ 둘 다 데이터를 바탕으로 미래나 새로운 정보를 예측하는 도구입니다.
2. 분류(Classification)란?
분류는 ‘정답이 범주(Category)’인 문제를 해결하는 방법입니다.
즉, 어떤 사물이 A인지, B인지 ‘이 중 하나’를 선택합니다.
📌 예시
- 메일이 스팸인지 아닌지
- 사진이 고양이인지 개인지
- 암 진단 결과가 양성인지 음성인지
- 고객이 이탈할지 Yes/No
결과는 항상 미리 정의된 범주 중 하나입니다.
→ 예측 결과: [‘스팸’, ‘정상’] 또는 [‘양성’, ‘음성’] 등
💬 일상 속 비유
- 선생님이 시험지 보고 학생이 A, B, C 중 어느 등급인지 평가하는 것과 같아요.
3. 회귀(Regression)란?
회귀는 ‘정답이 숫자(연속된 값)’인 문제를 해결하는 방법입니다.
즉, 특정 상황에 대해 얼마나? 몇 개? 몇 살? 등을 예측합니다.
📌 예시
- 아파트 가격 예측: 3억 2천만 원
- 내일 최고 기온 예측: 28.5도
- 유튜브 영상 조회수 예측: 120,000회
- 환자의 혈당 수치 예측: 142mg/dL
결과는 ‘숫자’이며, 무한히 다양한 값이 가능합니다.
💬 일상 속 비유
- 체중계에 올라갔을 때 체중을 숫자로 예측해주는 것과 같아요.
4. 한눈에 비교!
| 항목 | 분류 (Classification) | 회귀 (Regression) |
| 결과 형태 | 범주형 (A/B, 1/2/3 등) | 연속형 숫자 (정수/소수 포함) |
| 출력 예시 | 고양이/개, 합격/불합격 | 가격, 온도, 시간 |
| 모델 예시 | 로지스틱 회귀, SVM, 랜덤 포레스트 | 선형 회귀, 랜덤 포레스트 회귀, XGBoost |
| 평가 방법 | 정확도(Accuracy), 정밀도, F1 점수 | 평균 제곱 오차(MSE), R² 점수 등 |
| 활용 분야 | 의료진단, 스팸메일 구분, 감정 분석 | 주가 예측, 수요 예측, 날씨 예측 |
💡 모델 구조는 유사하지만,
결과 형태가 다르기 때문에 문제 정의부터 명확히 해야 합니다.
5. 실제 사례로 다시 비교해볼까요?
| 문제 | 분류 or 회귀? | 이유 |
| 이 메일은 스팸인가요? | 분류 | 결과가 스팸/정상 중 하나 |
| 이 집은 얼마일까요? | 회귀 | 결과가 가격이라는 숫자 |
| 이 사진은 강아지인가요, 고양이인가요? | 분류 | 미리 정의된 카테고리 중 하나 |
| 환자의 혈압 수치는 얼마일까요? | 회귀 | 예측 결과가 수치(숫자) |
6. 혼동하지 않는 팁
- “예/아니오”로 답할 수 있다면 → 분류
- “숫자로 답해야 한다면 → 회귀
- 둘 다 복잡한 모델을 쓸 수 있지만, 문제 정의가 먼저입니다.
✅ 머신러닝은 기술보다 **‘질문을 정확히 정의하는 능력’**이 더 중요합니다!
💬 마무리하며
분류와 회귀는 머신러닝의 ‘양대 축’입니다.
문제의 성격에 따라 어떤 모델을 쓸지 달라지기 때문에
둘의 차이를 정확히 아는 것이 AI 활용의 첫걸음이에요.
이제는 어떤 문제를 마주했을 때
“이건 분류 문제인가, 회귀 문제인가?”를 스스로 판단해보세요.
그 판단이 곧 ‘똑똑한 AI 활용’의 시작입니다.
✍️ 질문 드려요
여러분이 요즘 예측하고 싶은 건 어떤 정보인가요?
그건 ‘분류’일까요, ‘회귀’일까요?
댓글로 함께 고민해봐요
'기술 개념' 카테고리의 다른 글
| RAG란 무엇인가요? – AI의 한계를 보완하는 똑똑한 검색+생성 기술 (0) | 2025.04.24 |
|---|---|
| 좋은 AI는 데이터가 만든다 – 데이터셋 구축과 정제법 (0) | 2025.04.21 |
| 강화학습이란 무엇이고 어디에 쓰일까? (1) | 2025.04.01 |
| 컴퓨터 비전이란 무엇인가요? – 기계가 ‘눈’으로 세상을 이해하는 기술 (0) | 2025.04.01 |
| 자연어처리(NLP)란? – AI가 사람의 말을 이해하는 기술 (1) | 2025.04.01 |